Building Capybara; Hedvig's AI Chat Predictor

What does it actually mean to fine-tune a large language modal (LLM)? How do you do it? Does it work? These are questions I've been asking myself for a while. I finally got the chance to find out.
For Maker Days 2023 at Hedvig I joined a group of colleagues to build an AI modal that could predict what to respond to incoming member questions. We called it Capybara.
I learned a lot during these three days. Surprisingly, it isn't that hard to understand how LLMs can be fine-tuned to generate text that is relevant to a specific domain. Let me show you!
I will not go into detail about how the system works. This post will focus on the high-level concepts and how it all fits together.
The Problem
Hedvig is a digital insurance company. Through our app, members are able to chat with us using the chat. In some cases we can offer a complete self-service experience (including automatic payouts). In other cases, we need to involve a human or as we called them - our Insurance Experience Specialists (IEX). And let me tell you, they get a lot of questions. Therefore, we wanted to build a tool that could help them answer them faster.
The User Interface (web app)
I'm a product engineer so to me everything starts with the UI.

I wanted to build something that was intuitive to use and got out of the way when it wasn't helpful. Using or dismissing a suggestion should require minimal effort.
Therefore, we decided on a design where the suggestion is displayed as a placeholder text in the chat input field. The user can then choose to use the suggestion by pressing "Arrow Right" or dismiss it by starting to type. There's also a button to generate a new suggestion.
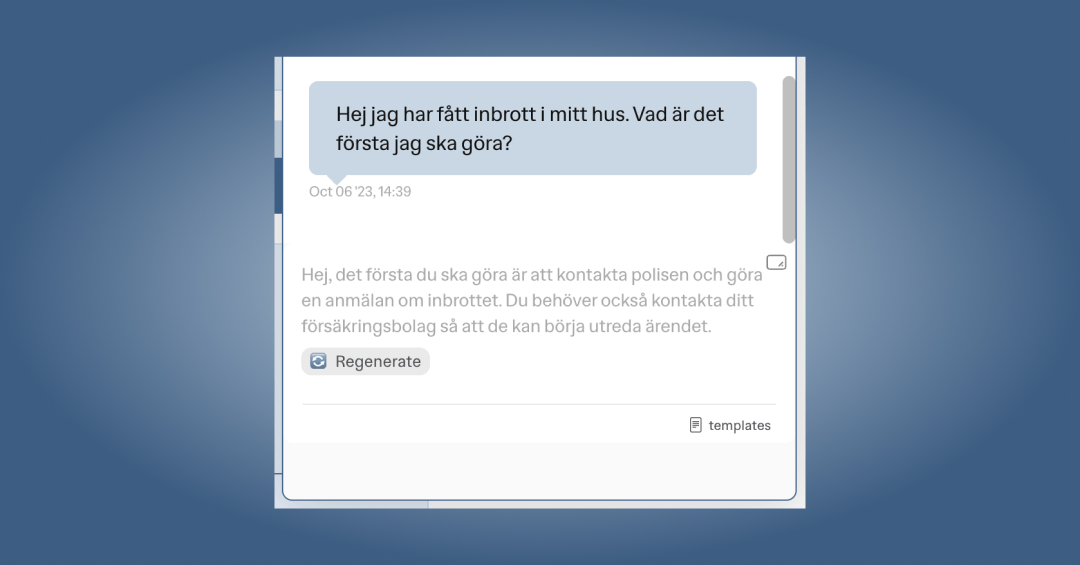
The Backend (API)
The web app talks to a backend API. It sends the message to be responded to and receives a suggested response. Behind the scenes, there a few more things going on.
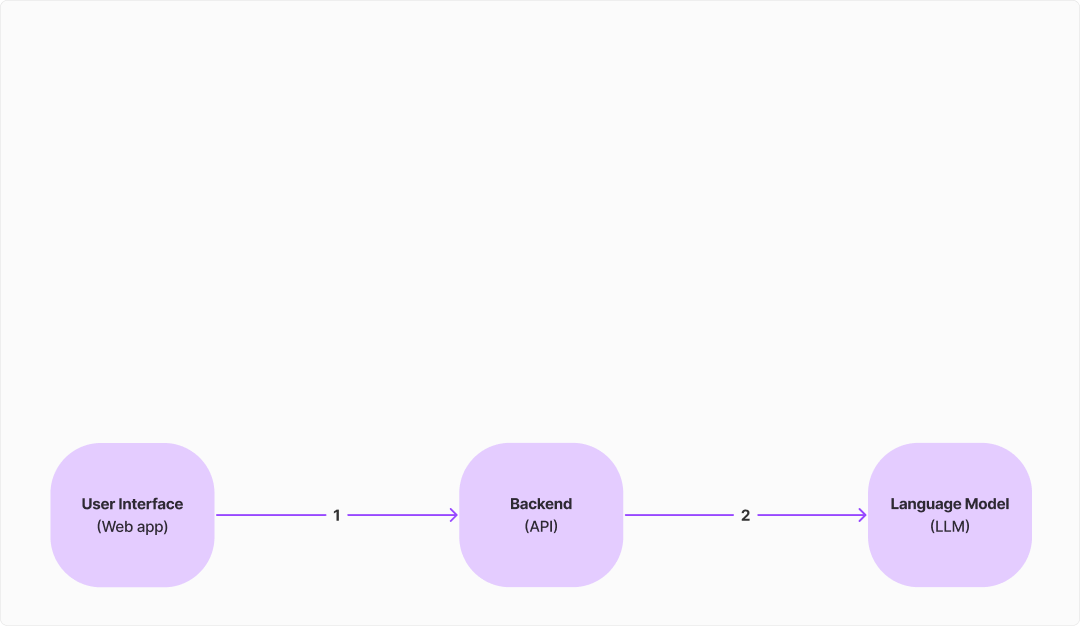
The backend calls a large language model (e.g. GPT-3) with the question to generate a response which can be sent to the client. However, we want the repsonse to be relevant to our domain (insurance) and tone of voice. To achieve this, we use a technique called "prompting". We prompt the model with 3-4 similar question-answer pairs from our chat history data.
In addition to the question-answer pairs, we also include various other static instructions in the prompt such as; "You are a customer service agent at the insurance company Hedvig" and "You are chatting with a member".
The Vector Database
How can the backend know what questions to prompt the model with? Given a chat message (question), we want to find similar questions (and the corresponding answers) from our chat history data.
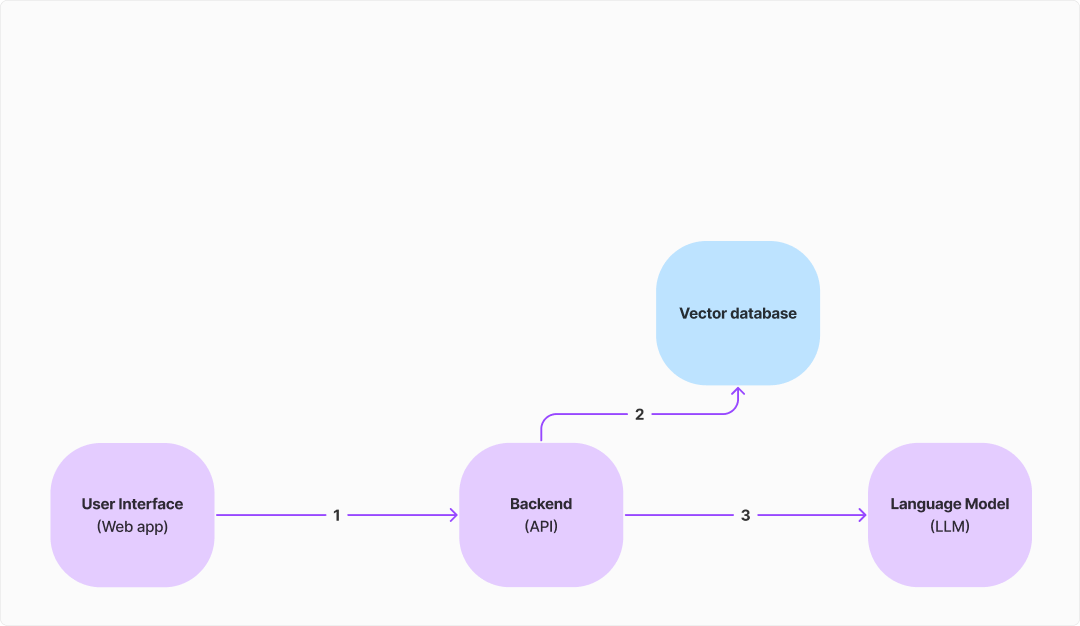
One way to do this is to store the chat history data in a vector database. That way, we are able to group simliar messages together. So all questions related to "How do I change my address?" would cluster together.
A vector is a list of numbers that represents a given text. The cool thing is that such vectors can be compared to each other. The distance between two vectors is a measure of how similar the two messages are. The closer the distance, the more similar the messages. It even works such that Vector(King) - Vector(Man) + Vector(Woman) = Vector(Queen)!
The Embedding Model
How do you transform a message into a vector? You use a so called embedding model; simply a model that has been trained to transform text into vectors.
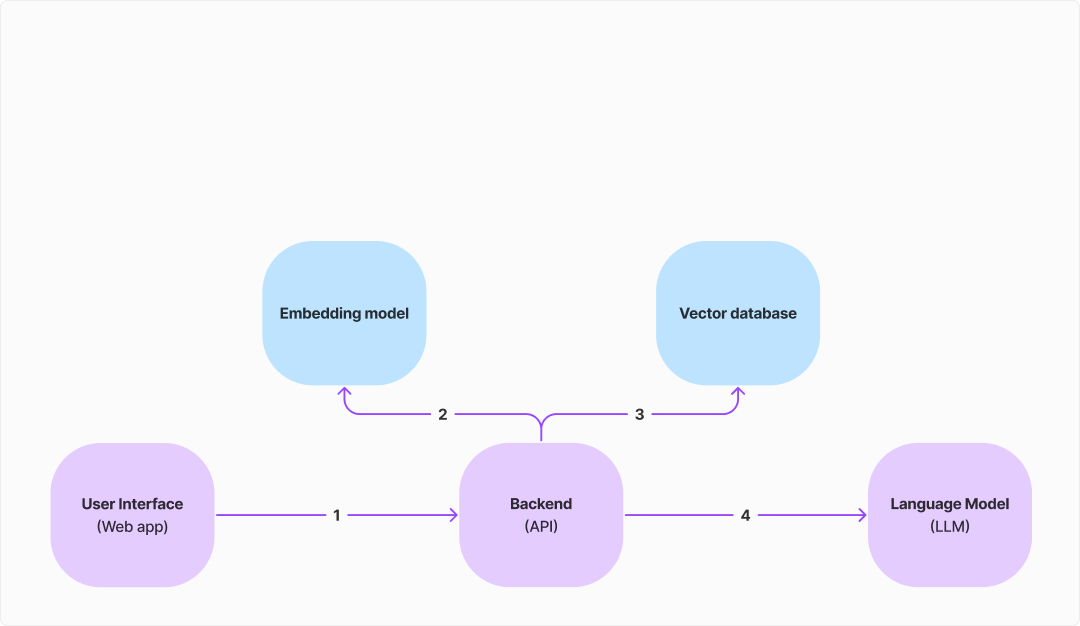
As we can see, the Backend API uses the same embedding model to transform the user message. It then uses the result to query the vector database for similar questions.
The Extract, Transform, and Load (ETL) Pipeline
We need to get the chat history data into the vector database. To do this, we developed an ETL pipeline.
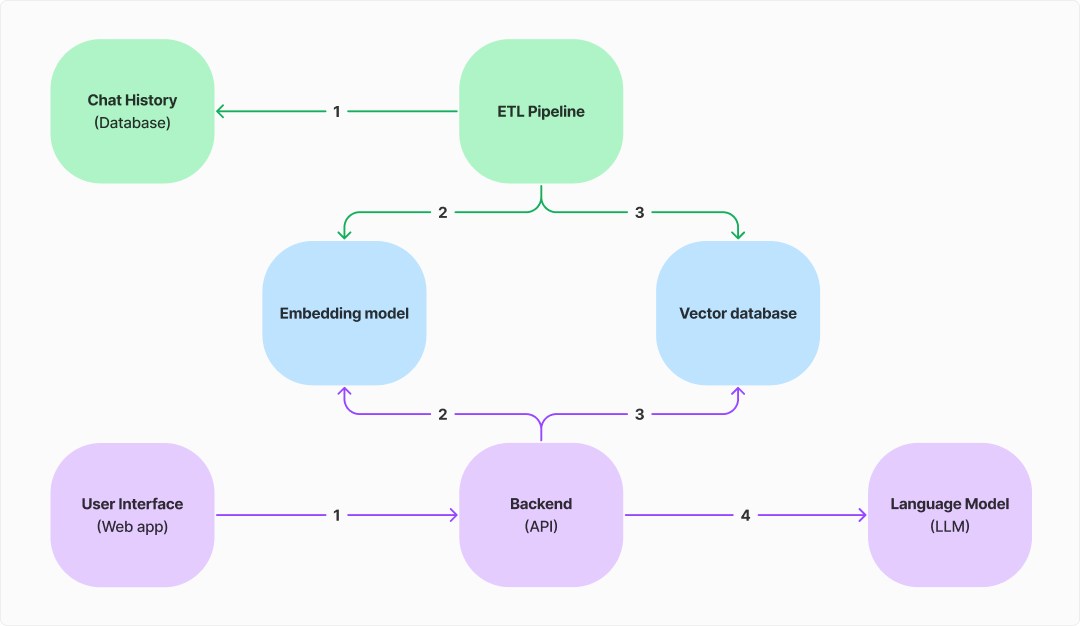
The pipeline extracts the data from our chat history database, filters out questions and corresponding answers, transforms the questions into vectors, and loads them into the vector database. This process was only run once but can be run again to account for new data.
Conclusion
How do you think it went? We did manage to build the whole system and use it to predict responses to incoming member questions! Most of the time went into figuring out various access issues and getting different parts to work together. The results were promising, especially for questions where we already have identified a good template response.
Another cool thing is that we can tell the LLM to respond in any language we want. It seems to work just fine to prompt it in English, use Swedish examples and just ask it to respond in the same language as the original question!
Still, the LLM is still missing a lot of context. Both in terms of the domain (terms and conditions) and the member (e.g. what insurance they have). It would be interesting to see how much better the results would be if we included this information in the prompt.

